
Microbiologie in hapklare porties
Een nieuwe letter in het genetisch alfabet.
Alle DNA op aarde heeft hetzelfde “alfabet”. Van virussen tot mensen worden A, C, T en G gebruikt. Deze vier nucleotiden (Adenine, Cytosine, Thymine en Guanine) zijn de bouwstenen voor de genetische code van alle organismen en virussen.
Nouja… Elke regel heeft een uitzondering! Al in 1977 werd in de bacteriofaag S-2L (die cyanobacteriën infecteert) in plaats van A een chemisch verwante nucleotide gevonden: diaminopurine, afkorting Z. Chemische modificaties op DNA komt vaker voor, maar in dit geval werd A compleet vervangen en het vormde de “nieuwe” nucleotide basenparen met T.

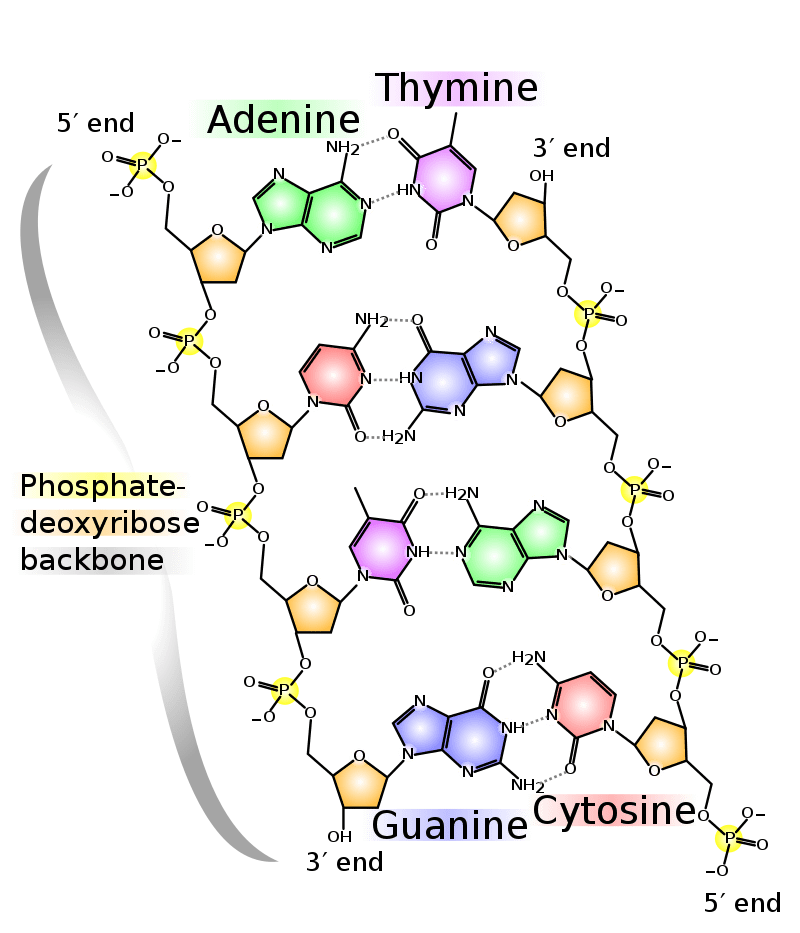
Sindsdien hebben andere onderzoeken geprobeerd erachter te komen hoe deze nieuwe nucleotide wordt gesynthetiseerd en in het DNA functioneert, maar we zijn er nog niet veel wijzer uit geworden. Om dat onderzoek te begrijpen moeten we weten hoe DNA in elkaar zit. De naam DNA is een afkorting van het Engelse deoxyribonucleic acid (Nederlands: desoxyribonucleïnezuur) en beschrijft de chemische structuur van de blauwdruk des levens.
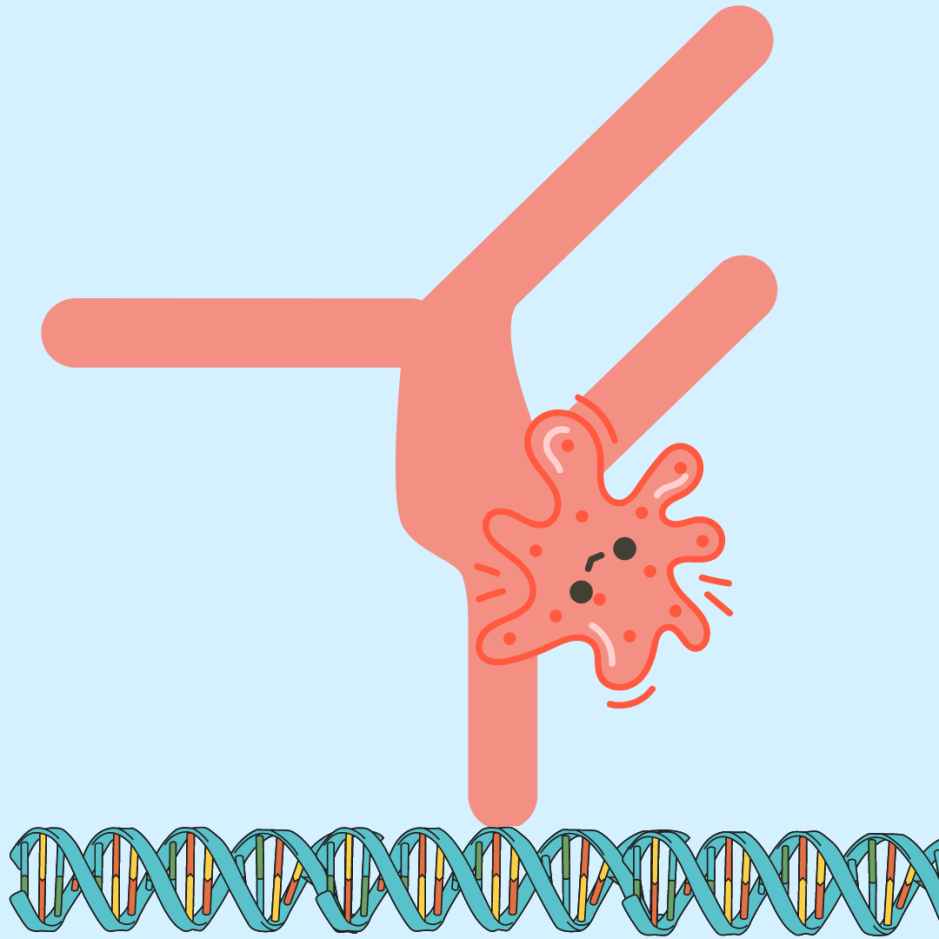
Een lange ruggengraat bestaat uit fosfaatgroepen (vandaar de zure eigenschap) en de suiker 2-desoxyribose. Het nucleïne-deel van de naam verwijst naar een zijgroep die bepaalt of de base A, C, T of G is. Twee ketens van nucleotiden worden bij elkaar gehouden door waterstofbruggen en vormen daarbij vanzelf de karakteristieke “dubbele helix”. Deze twee ketens liggen in tegenovergestelde richting A en T vormen twee waterstofbruggen, G en C vormen er drie (zie afbeelding).
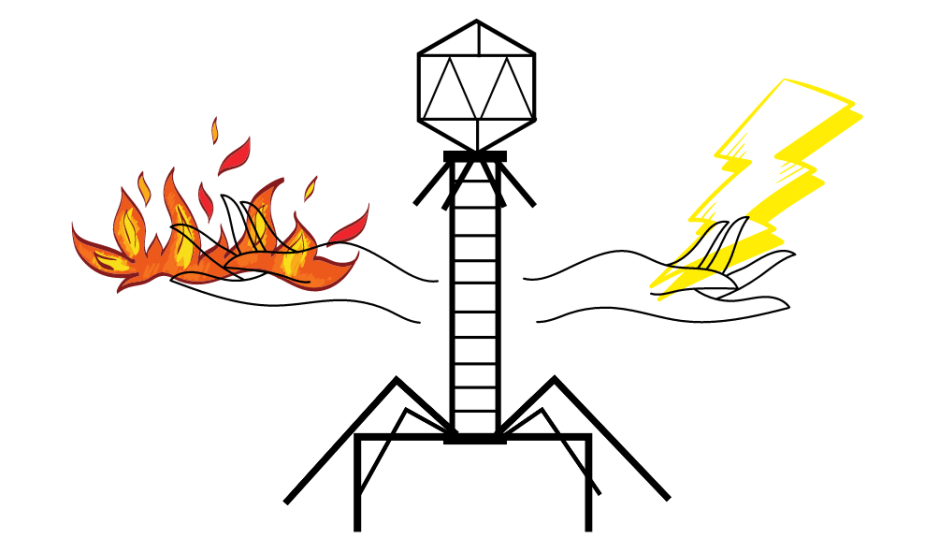
In 1998 werd uitgevonden dat het Z-T basepaar van de bacteriofaag S-2L drie waterstofbruggen vormt (hier meer over bacteriofagen). Dat verandert de 3D-structuur van het DNA.

Het duurde tot april 2021 voordat dezelfde “uitzondering” in andere bacteriofagen werd gevonden door Franse en Chinese onderzoeksgroepen. Ze publiceerden artikelen over de biosynthese van nucleotide Z, en de implicaties van de uitzonderlijke nucleotide voor het virale DNA (REF1, REF2, REF3).
De groepen van Yan Zhou en Dona Sleiman toonden aan dat Z ook door andere bacteriofagen wordt gebruikt, en een derde onderzoek richtte de aandacht op één specifieke virussoort Vibrio Phi-VC8. Om te bestuderen hoe Z wordt gebruikt in de verschillende virussen, bekeken de groepen van Zhou en Sleiman de biosynthese-route en in het bijzonder het enzym PurZ.
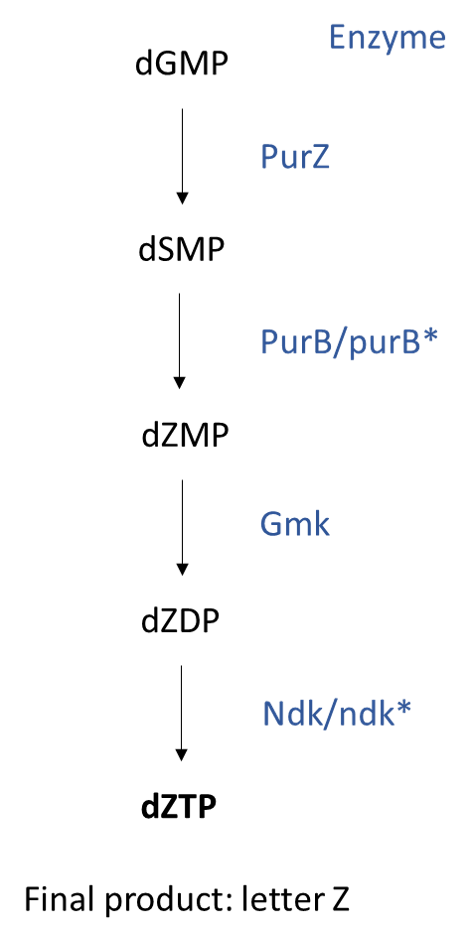
Met een aantal mutante virus-stammen konden Sleiman en collega’s aantonen welke enzymen nodig zijn voor het maken van de nieuwe nucleotide en konden ze laten zien dat Z-trifosfaat (dZTP) gemaakt wordt van G-monofosfaat (dGMP). Virussen zonder functioneel PurB-enzym infecteerden cellen slechter, en zonder Ndk-enzym lukte dat helemaal niet meer. Dit onderzoek laat uiteindelijk zien dat deze genen nodig zijn voor de synthese van Z-trifosfaat, en dat de virussen niet zonder deze nucleotide kunnen reproduceren.
Het onderzoek van Valerie Pezo en collega’s richtte zich op DNA-machinerie, en in het bijzonder op DNA-polymerase (hier meer over DNA-machinerie). DNA-polymerasen worden gebruikt om DNA te kopiëren: het enzym bindt aan één van twee DNA-strengen in een helix en schuift in de richting van 5’ naar 3’ over de keten. Het enzym synthetiseert een nieuwe DNA-streng van complementaire basen (A bij T, C bij G en vice versa) vanuit trifosfaat-nucleotiden (dATP, dTTP, dCTP, dGTP).
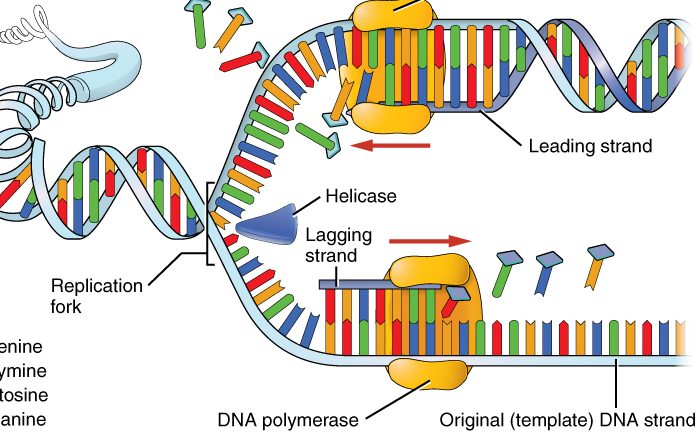
De vraag is nu: hebben de bacteriofagen een ander DNA-polymerase om Z-trifosfaat (dZTP) te herkennen als ze hun DNA kopiëren? Het onderzoek toonde aan dat de DNA-polymerasen van virus-soorten die Z in hun genoom hebben, 30 tot 90 keer efficiënter dZTP konden omzetten dan dATP. De DNA-polymerase van Escherichia coli (zonder Z in het genoom) kon 2 keer efficiënter dATP gebruiken in vergelijking met dZTP, wanneer beide aanwezig zijn in de bacteriecel. Het lijkt er dus op dat virussen met Z in het genoom een speciaal geëvolueerde DNA-polymerase voor de nieuwe letter in het DNA-alfabet hebben.
Waarom hebben deze virussen eigenlijk een nieuwe letter? Zhou en collega’s denken dat DNA met een nieuwe letter minder makkelijk wordt herkend door restrictie-enzymen (een veelgebruikt afweermechanisme door virus-gastheren). Als we meer leren over deze nieuwe letter in het DNA-alfabet kunnen we het bijvoorbeeld toepassen in DNA origami of ”DNA-based data storage”. Daarnaast zouden we de virussen kunnen modificeren voor efficiëntere faag-therapie of verbeterde conservering van voedsel.
Misschien zijn er nog meer letters in het DNA-alfabet die nog ontdekt kunnen worden wanneer we meer organismen en virussen onderzoeken. De mens heeft wel geprobeerd om zelf nieuwe letters te ontwikkelen, maar het lijkt erop dat de natuur de klus al heeft geklaard.
Link naar het originele artikel:
Featured image: Modified from: https://innovativegenomics.org/glossary/dna/